Yelp Dataset Challenge 2017
Date
November 16, 2017
Category
Classification, Collaborative Filtering, Data Analysis, Data Visualization, Decision Tree, K-Means, LDA, Matrix Factorization, Model Building, PCA, Python, Random Forest, YelpI analyze three sub datasets in Yelp Dataset Challenge 2017 in answering these three questions:
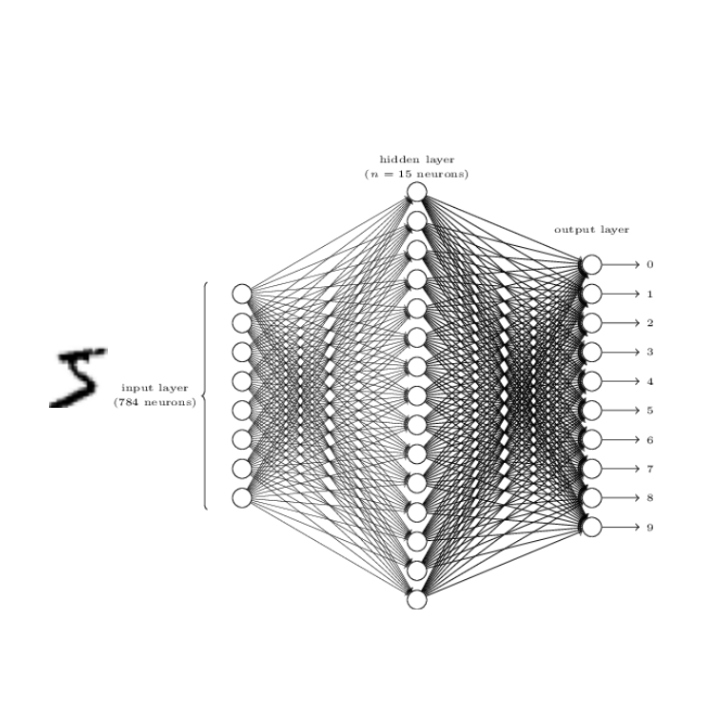
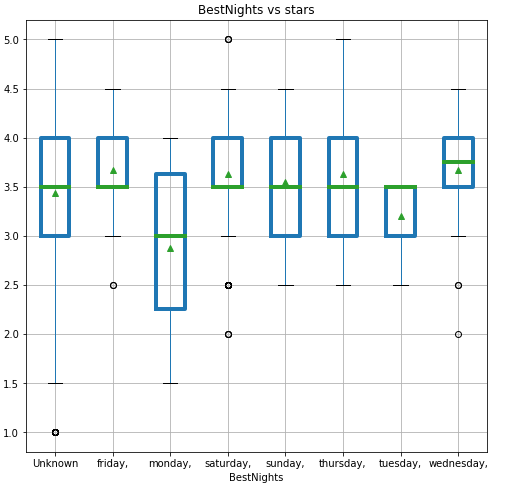
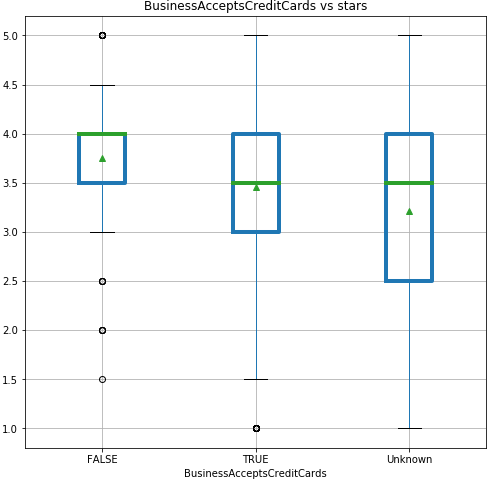
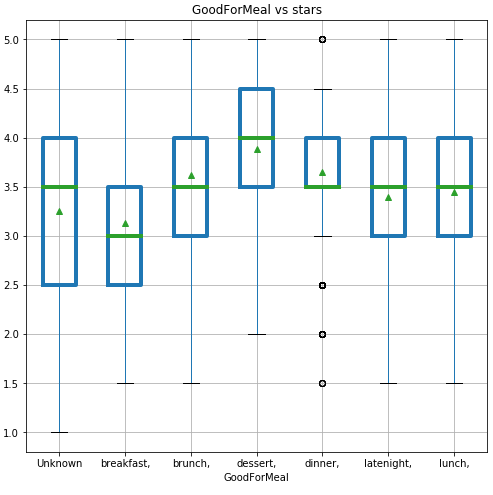
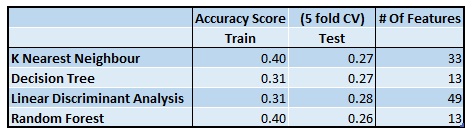
1. Could we classify ratings just by looking at the restaurants’ features? The answer is no. Given the low accuracy score of four classification models, we can’t just rely on the restaurant
features alone to classify the ratings. However, these features will be helpful for future analysis.
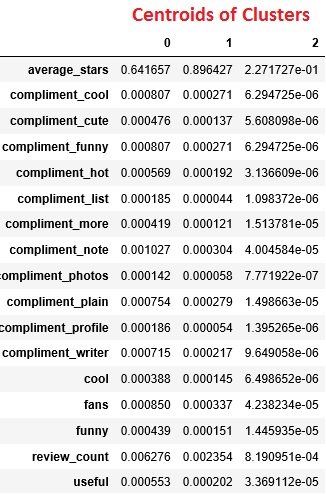
2. Do Yelp users share some common characteristics when their given average ratings are close? The answer is yes. If your average rating is in the middle-level yelp users(in another way, you are not too critical or too easy to satisfied), you will receive more compliments from others. People are more likely to think your reviews are helpful or cool. However, if your average ratings are extremely low, then people are less likely to compliment your reviews.
3. Could we use the ratings alone to perform collaborative filtering and matrix factorization to predict ratings The answer is yes. Although I only use a sample size of 8,000 out of 850,000 records, the performance of the collaborative filtering model is very good with only 1.69 in MAE for 7,389 users and 5,682 restaurants.